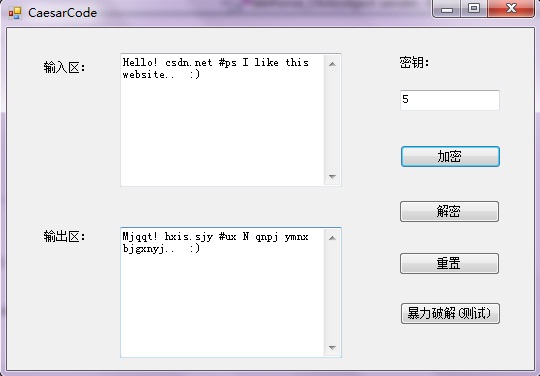
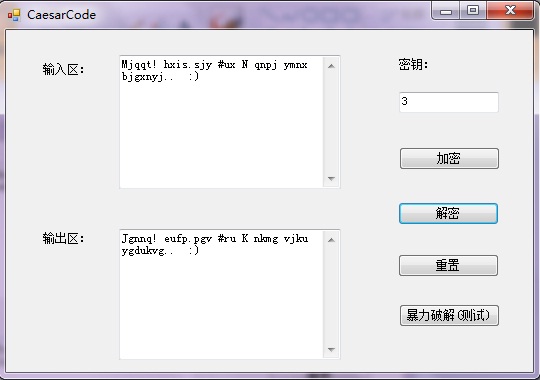
privatevoidCaesar(int choose) { bool flag; int key; int len; int i; int member; string info = info = txtInput.Text; flag = int.TryParse(txtKey.Text, out key);
if (flag == true && info.Length > 0) { if (choose != 1) key = -key;
txtOutput.Clear(); len = info.Length; for (i = 0; i < len; i++) { member = info[i]; if (member >= 'a' && member <= 'z') { member = (member + key % 26); if (member < 'a') member = (member + 26); if (member > 'z') member = (member - 26); txtOutput.Text += (char)member; } elseif (member >= 'A' && member <= 'Z') { member = (member + key % 26); if (member < 'A') member = (member + 26); if (member > 'Z') member = (member - 26); txtOutput.Text += (char)member; } elseif (member >= '0' && member <= '9') { member = (member + key % 10); if (member < '0') member = (member + 10); if (member > '9') member = (member - 10); txtOutput.Text += (char)member; } elseif (member >= 0 && member <= 47) { member = (member + key % 48); if (member < 0) member = (member + 48); if (member > 47) member = (member - 48); txtOutput.Text += (char)member; } elseif (member >= 58 && member <= 64) { member = (member + key % 7); if (member < 58) member = (member + 7); if (member > 64) member = (member - 7); txtOutput.Text += (char)member; } elseif (member >= 91 && member <= 96) { member = (member + key % 6); if (member < 91) member = (member + 6); if (member > 96) member = (member - 6); txtOutput.Text += (char)member; } else { txtOutput.Text += (char)(member + key); } } } else { MessageBox.Show("密钥输入有误!/文本出现错误!"); txtKey.Clear(); txtKey.Focus(); } }