极狐GitLab自动化测试指南02——接口测试
1 理论篇
1.1 什么是接口测试
WIKI百科对于接口测试的解释是:
接口测试是软件测试的一种,它包括两种测试类型:狭义上指的是直接针对应用程序接口(下面使用缩写API指代,其中文简称为接口)的功能进行的测试;广义上指集成测试中,通过调用API测试整体的功能完成度、可靠性、安全性与性能等指标。
接口测试根据其测试目的不同,来决定测试人员和测试方法:
WIKI百科对于接口测试的解释是:
接口测试是软件测试的一种,它包括两种测试类型:狭义上指的是直接针对应用程序接口(下面使用缩写API指代,其中文简称为接口)的功能进行的测试;广义上指集成测试中,通过调用API测试整体的功能完成度、可靠性、安全性与性能等指标。
接口测试根据其测试目的不同,来决定测试人员和测试方法:
WIKI百科对于软件测试的定义是:
在规定的条件下对程序进行操作,以发现程序错误,衡量软件质量,并对其是否能满足设计要求进行评估的过程。
软件测试是伴随着计算机和软件开发的发展而发展的,有记录的信息可以追溯到1958年的美国第一个载人航天计划——水星计划,在该计划中首次描述了软件测试团队及其工作内容。从软件测试出现到现在,大致可分为五个阶段:
调试为导向:20世纪50年代初期,当时还没有明确测试(Testing)和调试(Debugging)之间的区别,所以也没有测试或测试人员的概念。开发人员主要是以调试为主,验证程序是否符合预期。
证明为导向:1957年,Charles L Baker在对Dan McCracken的著作《Digital Computer Programming》进行评审时,提出了测试的概念,并对调试和测试进行了区分:
1957年到1978年,软件测试的主要目标是确保软件满足功能需求,也就是我们常说的“做了正确的事情”。
破坏为导向:1979年,Glenford J. Myers在《The Art of Software Testing》一书中阐述了一个成功的测试用例是检测到尚未发现的错误。说明测试不仅要证明软件做了正确的事情,也要保证它没做不该做的事情。这也使得软件测试和软件开发独立开来,测试需要更为专业的人员进行,毕竟开发人员在心理上总是不愿意给自己开发的软件找错。
评估为导向:1983年,出现了大名鼎鼎的V&V(验证和确认)理论,也就是现在测试人员熟悉的V模型,软件测试被应用在整个软件生命周期(SDLC)中。 这段时期软件测试的重点是检验它是否满足规定的需求或弄清预期结果与实际结果之间的差别,以及通过测试来评估和衡量软件质量。

预防为导向:1988年至2000年提出了一种新的测试思路。代码被分为可测试的和不可测试的,可测试的代码比难以测试的代码更少,所以测试的重点应该是在代码级别防止缺陷。20世纪的最后十年出现了探索性测试,测试人员探索并深入了解软件,试图找到更多的错误。2000年前后也出现了测试驱动开发(TDD)和行为驱动开发(BDD)等新概念的兴起。而2004以后,伴随敏捷开发模式的推广,自动化测试工具和持续集成等技术的应用,都体现出人们不再满足于传统的、后置的仅保证功能正确的软件测试,而是希望尽早的、高效的、全面的发现和识别问题。
企业内部一般都会有多个业务、应用系统,为建立统一的用户管理、身份配给和身份认证体系,实现一个账号登录所有系统,需要建立一套统一身份认证服务平台。
统一身份认证服务平台一般包含以下几个部分:
而单点登录(SingleSignOn,SSO),不光可以实现一个账号登录所有系统,它通过用户的一次性登录认证,就可以访问多个应用。SSO一般会被包含在认证管理功能里。
GitLab支持多种身份认证和授权方式,可以与企业的统一身份认证服务平台集成。包括对接AD/LDAP实现统一账号,对接SAML、CAS、Auth0、OAuth2等实现SSO。GitLab对于AD/LDAP、SAML、CAS、Auth0的对接提供了详细的文档。而对接Generic OAuth2的文档较粗放,网络上也没有太多参考资料,所以整理了一篇GitLab对接OAuth2的实践文章。
使用GitLab CICD,在部署方面,主要有两种方式:
部署到K8S集群
Push模式:流水线通过kubectl执行命令部署,这需要把K8S的权限给流水线,存在安全风险
Pull模式:使用GitLab Agent for Kubernetes或ArgoCD,通过GitOps的方式“监听”GitLab的变化,触发部署

部署到服务器
目前仍有不少企业因为行业性质或者场景所限,没有使用K8S等云原生技术,还在采用传统的服务器方式进行部署。一般使用ssh、scp、rsync等命令部署到服务器。GitLab也提供了基于SSH keys的部署。详见:Using SSH keys with GitLab CI/CD | GitLab
需要说明的是,如果是使用专用的编译机进行编译构建,然后部署到指定的服务器,只需要实现编译机和部署服务器的免密SSH登陆即可,相对简单。但如果使用容器进行编译构建,然后部署到服务器,就需要按照上面文档中提到的,配合GitLab CI/CD环境变量,将SSH_PRIVATE_KEY等变量存储到GitLab Project、Group或Instance中,实现复用。且可以通过GitLab CI/CD环境变量的Mask设置,掩藏这些变量在CICD日志中的显示。详见:GitLab CI/CD variables | GitLab
但遗憾的是Mask功能目前是有限制的,对于SSH_PRIVATE_KEY这种多行的变量无法直接使用Mask功能。这样开发人员就可以在.gitlab-cti.yml文件的脚本中执行echo $SSH_PRIVATE_KEY,在流水线的日志中输出SSH Keys,存在密钥泄露风险。
The value of the variable must:
- Be a single line.
- Be 8 characters or longer, consisting only of:
- Characters from the Base64 alphabet (RFC4648).
- The
@and:characters (In GitLab 12.2 and later).- The
.character (In GitLab 12.10 and later).- The
~character (In GitLab 13.12 and later).- Not match the name of an existing predefined or custom CI/CD variable.


这个问题在GitLab的Issue上挂了有一年多 ,看样子短时间没法解决。有没有其他方式Mask SSH_PRIVATE_KEY?于是开始了各种折腾。
WARNING:本文含有强烈的刺激性气味,请勿在进食期间阅读。如感到血压上升、眩晕、呼吸急促,请立即停止阅读。
祖传代码(Legacy Code),就字面意思而言,就是无数的前任程序猿留给你的最后遗产。这些代码几乎没有可维护性,缺少注释、命名不规范、依赖错综复杂,你根本读不懂它,但神奇的是它们都能跑起来。不要试图修改它们,因为要么就无从下手,要么一改就出大问题。每家公司都会有那么些“历史遗留问题”。亚马逊的工程师亲切的形容他们的祖传代码为“屎山”:“每次你想修正一个bug,你的工作就是爬到屎山的正中心去”。

一家企业里,偶尔一两座屎山无伤大雅,毕竟每家企业都有很长的故事。但如果“你看那一座座山,一座座山川,一座座山川相连”,这种情况就很危险了。山路十八弯,难以持续的为企业快速增长提供高效支撑。企业发展的越快,屎山的债务积累就越多,形成恶性循环,最终企业员工只能望山兴叹,下山逃难去了。如何解决屎山问题?如何形成一个正向的发展循环?如何打造一个研发流程的最佳实践?如何加强质量内建?那我们就要先爬到屎山的正中心去一探究竟,明知山有屎,偏向屎山行。
RSS介绍,摘自WIKI百科:
RSS(全称:RDF Site Summary;Really Simple Syndication),中文译作简易信息聚合,也称聚合内容,是一种消息来源格式规范,用以聚合经常发布更新资料的网站,例如博客文章、新闻、音频或视频的网摘。RSS文件(或称做摘要、网络摘要、或频更新,提供到频道)包含全文或是节录的文字,再加上发布者所订阅之网摘资料和授权的元数据。简单来说 RSS 能够让用户订阅个人网站个人博客,当订阅的网站有新文章时能够获得通知。
RSS摘要可以借由RSS阅读器、feed reader或是aggregator等网页或以桌面为架构的软件来阅读。标准的XML档式可允许信息在一次发布后透过不同的程序阅览。用户借由将网摘输入RSS阅读器或是用鼠标点取浏览器上指向订阅程序的RSS小图标之URI(非通常称为URL)来订阅网摘。RSS阅读器定期检阅是否有更新,然后下载给监看用户界面。
RSS的黄金年代早已随着2013年Google Reader的下线而逝去,随之而来的是各种聚合类新闻APP,它们利用实时推送提高了信息传递的速度,利用推荐算法实现了信息传递的精准度。然而在这个信息爆炸的时代,良莠不齐的内容、低俗偏激的评论,大数据+人工智能精心打造的信息茧房真的适合人们去阅读去思考吗?
对信息来源、信息内容、信息实时性有要求,希望操作界面简单、适合阅读、跨平台。在2021年,利用RSS打造这样一个信息聚合服务,依然是小众之选,但却可以获得更纯粹的阅读体验。
部分内容整理自:
面试必问:分布式事务六种解决方案 - 知乎 (zhihu.com)
10分钟说透Saga分布式事务 - 云+社区 - 腾讯云 (tencent.com)
部分内容整理自:
https://www.cnblogs.com/yiwangzhibujian/p/7047458.html
https://blog.csdn.net/striveb/article/details/95110502
https://mp.weixin.qq.com/s/2OTVJUTLOetYTD4Hpk-hFA
https://juejin.cn/post/6844903663224225806
纯内存操作
Redis是一个KV内存数据库,它内部构建了一个哈希表,根据指定的KEY访问时,只需要O(1)的时间复杂度就可以找到对应的数据。同时,Redis提供了丰富的数据类型,并使用高效的操作方式进行操作,这些操作都在内存中进行,并不会大量消耗CPU资源,所以速度极快。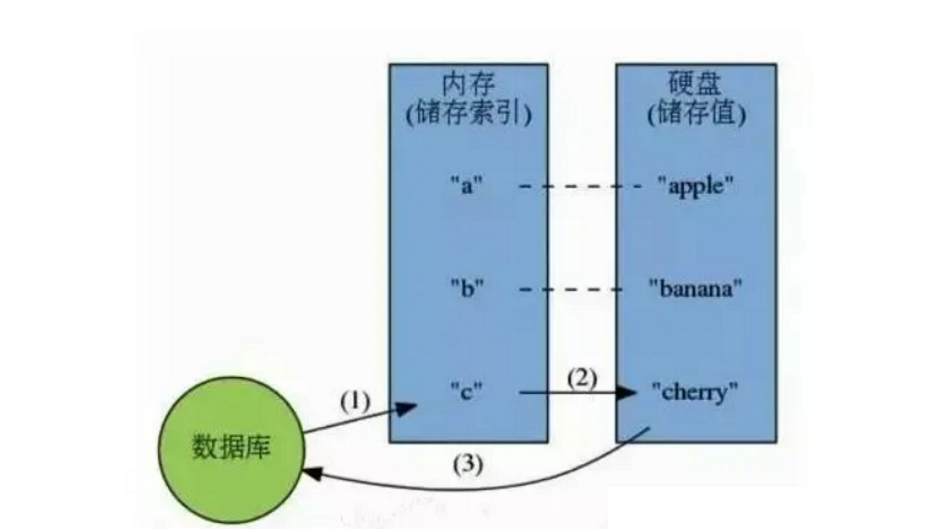
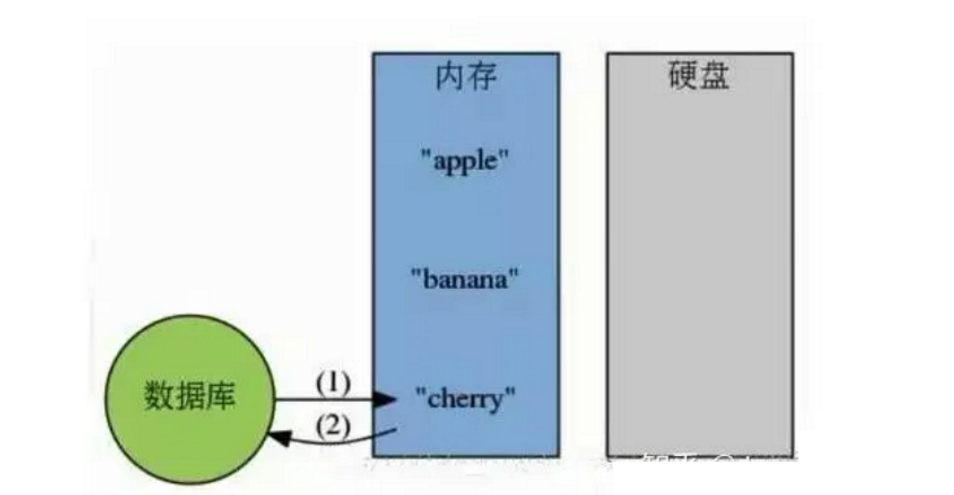
单线程
使用IO多路复用技术
非CPU密集型任务
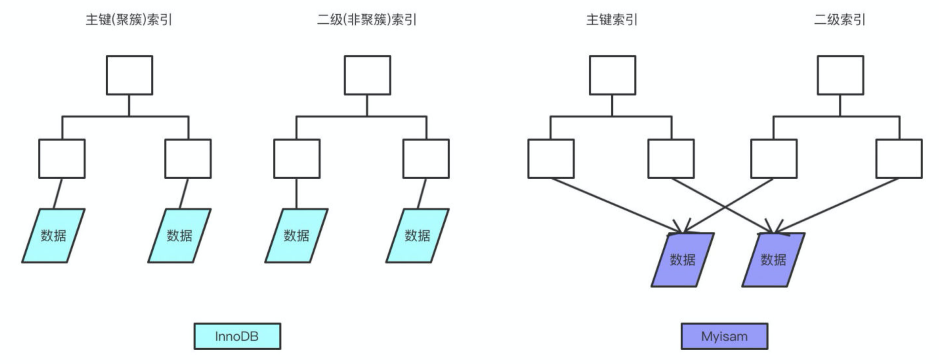
B+树和Hash索引
B+树是左小右大的顺序存储结构,节点只包含id索引列,而叶子节点包含索引列和数据,这种数据和索引在一起存储的索引方式叫做聚簇索引,一张表只能有一个聚簇索引。假设没有定义主键,InnoDB会选择一个唯一的非空索引代替,如果没有的话则会隐式定义一个主键作为聚簇索引
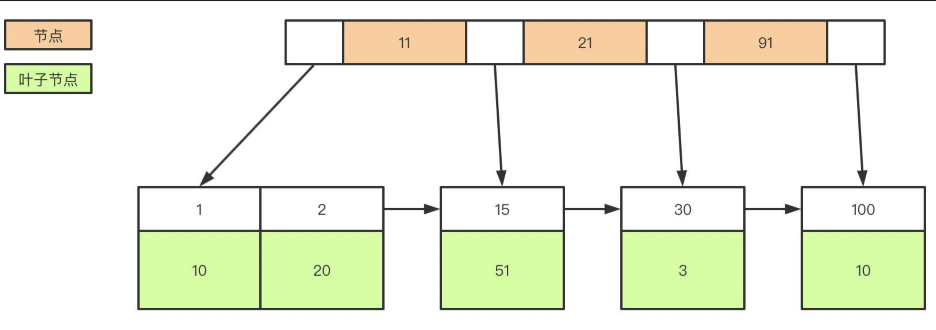
非聚簇索引(二级索引)保存的是主键id值,这一点和myisam保存的是数据地址是不同的
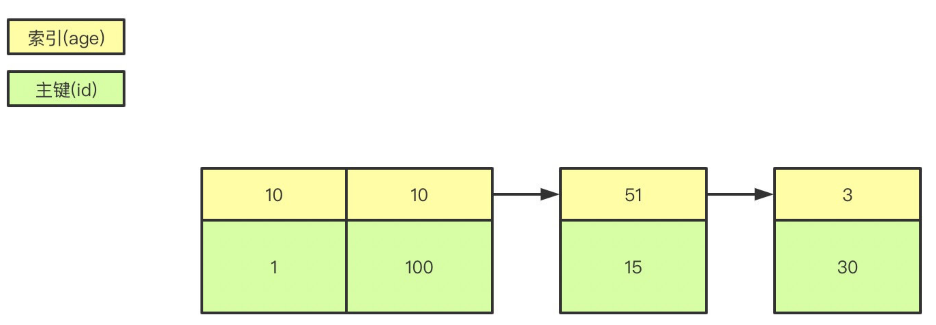
区别